距离上次博文已经有快半年了。原本打算在过年期间写一篇2019年的回顾和总结。但也被这突如其来的疫情打乱。放假期间一直关注相关新闻导致信息过载,一度非常沮丧。
2月复工以后,停止了疫情信息的摄取,反倒心理上轻松不少。人都是健忘的,可不是吗?
言归正传,上篇博文说遇到一个服务假死的问题,具体现象就是服务不再接收任何请求,客户端会抛出Broken Pipe。正好最近又重现了,并且找到了root cause。
检查状态
系统状态
依然从全局入手,执行top查看发现负载很低,cpu都在10%以下,说明不是计算密集的问题,基本可以感觉是io或者是jvm垃圾回收有异常。另外查询系统情况推荐dstat这个工具,蜜汁好用。
1 | dstat -lcdngy |
JVM状态
因为开启了gc log,所以先检查一下是不是有频繁的full gc,当然上手就jstat不犹豫也是没问题的。
1 | 2020-02-19T17:32:59.041+0800: 5618.660: Application time: 0.9945668 seconds |
大概有十几个Full GC,原因都是 Allocation Failure。特别值得注意的是,GC前eden的占用是100%,s0的占用是99%,此时还有Allocation Failure说明old区也满了。eden和s0的对象都无法通过Young GC回收,年轻代对象继续向old区晋升,但是old区也满了,导致 Allocation Failure 触发Full GC,而且耗时7.68 secs,这可是STW啊,整个系统都暂停响应了。再看GC后的情况,年轻代都清零了,说明并不是有内存泄露导致无法回收。而是短时间有大量新对象被创建,Young GC来不及回收,直到新对象不断晋升到老年代导致的STW。
那么接下来就开始追查什么原因会创建这么多新对象,手头缺一个最好的证据,就是Full GC时的heap dump。开启jstat不停的刷,等到old区快满的时候,抓dump。
时机正好,通过jmap导出dump文件
1 | jmap -dump:format=b,file=/tmp/heap.hprof 1 |
一看文件足足有6g,说明真的是待回收的对象太多了。
分析Dump
使用mat打开这个dump文件都花了半小时,风扇呼呼的在抗议。一个小tip,记得把mat的Xmx调大,不然会崩掉。另外由于这次并不是内存泄露造成不可回收,所以需要打开mat的Keep unreachable objects去分析不可触达的对象。
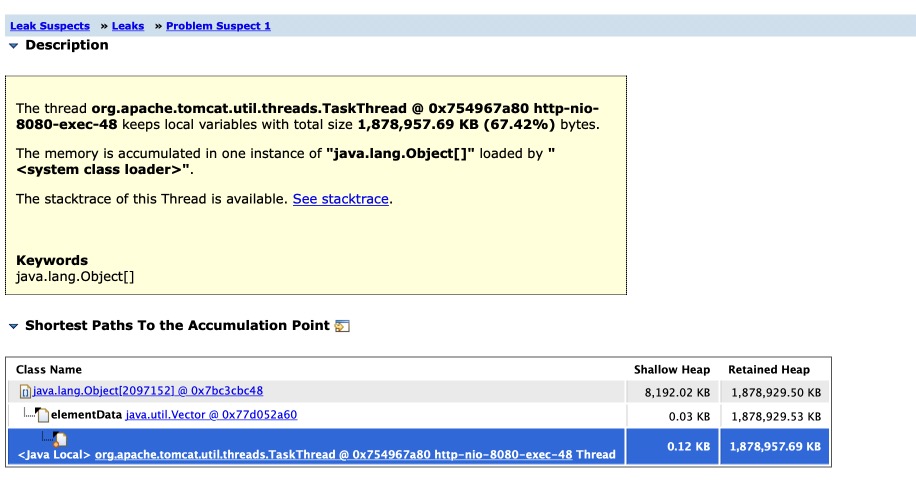
打开lead suspects可以看到最大的是java.lang.Object[],这也印证了大量对象被创建并被加入数组的猜测。
Root cause
那么究竟是什么操作引发的呢?在mat的报告中最终发现这个object是一个entity类,说明这是一个数据库操作,查询出了大量结果导致的。
这种查询量级一定会被记录为了慢查询,打开阿里云的RDS慢日志查询

218w的记录被查询到,没有直接OOM算是走运了。
但是查询的sql很奇怪,出现了is null的条件语句,由于这个字段是索引字段应该精确匹配的,业务逻辑中不可能出现查询空记录的需求。repository的查询接口是使用spring-data-jpa标准描述的。
1 | Person findByAAndBAndC(String A, String B, String C); |
理论上应该转化为
1 | select * from person where A=A and B=B and C=C; |
结果却变成了
1 | select * from person where A is null and B=B and C=C; |
这样以来,就跳开了索引并查询到相当可观的记录。经过试验发现如果未经过判空校验,当A=null时,spring-data-jpa会自动转化为is null的SQL语句。
最终我们对所有类似调用都加上了Assert.notnull的处理。重新上线后问题解决,再也没有FGC发生了。
总结
对于程序员来讲,这种“智能”的框架真的是非常可怕,当你面对一个黑盒的时候,灾难往往就在不远处。
